Introduction
HPL(High Performance Linpack)是Linpack Benchmark的组成部分之一,采用LU分解的高斯消元法求解大型稠密线性方程组: Ax=b,由美国田纳西大学的Jack Dongarra创作并维护,目前是评测高性能计算机系统性能的事实标准。
HPCG(High Performance Conjugate Gradients)是共轭梯度法求解大型系数矩阵方程组:Ax=b,由美国 Sandia 国家实验室的 Michael A. Heroux创作并维护,访存密集型,更能反应科学计算领域的负载特征。
大作业要求在HPL和HPCG中二选一做优化,需要完成以下内容:
Course project :
- run HPL / HPCG correctly
- profiling and analyze the performance
- changing input parameters (C)
- replace kernel function by the other lib or opensource code(B)
- manual optimization (A)
HPL
运行HPL需要:
- BLAS(Basic Linear Algebra Subprograms基础线性代数程序集)是进行向量和矩阵等基本线性代数操作的事实上的数值库。这些程序最早在1979年发布,是LAPACK(Linear Algebra PACKage)的一部分,便于建立功能更强的数值程序包。BLAS库在高性能计算中被广泛应用,由此衍生出大量优化版本,如Intel的Intel MKL,AMD的ACML,Goto BLAS和ATLAS等非硬件厂商优化版本,以及利用GPU计算技术实现的CUBLAS等。
- MPI(Message Passing Interface)是一个跨语言的通讯协议,用于编写并行计算机。支持点对点和广播。MPI的目标是高性能,大规模性,和可移植性。使用MPI可以充分利用多台计算机的计算资源,提高计算效率和性能,是高性能计算领域的重要技术之一。MPI在今天仍为高性能计算的主要模型。
LU分解相关的内容见LU分解的高斯消元法求解线性方程组
但是只使用高斯消元法进行运算,有可能会因为除0而计算失败,因此HPL中使用列选主元高斯消元法,来控制高斯消元法避免除0。
列选主元就是每次运算选取列中的最大元素作为主元,用于该列的消元运算(这里有点问题,具体是怎么交换的?)。
HPL递归分解流程如下图所示:
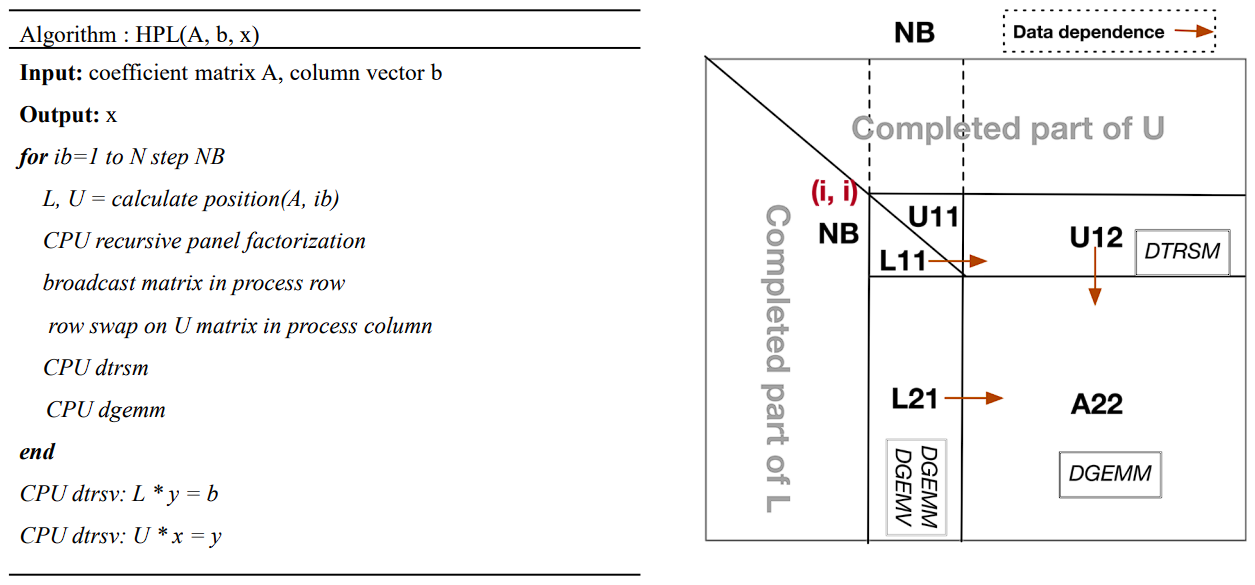
更加直观的:
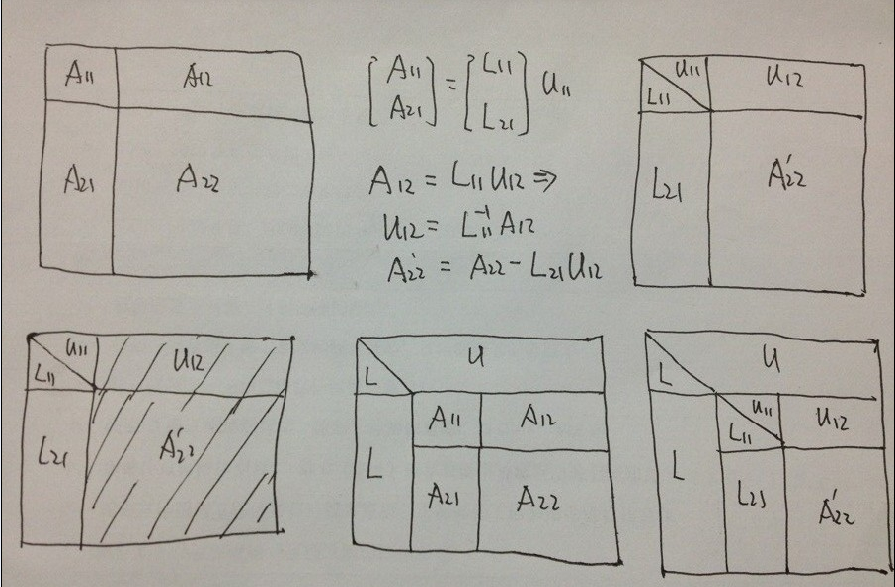
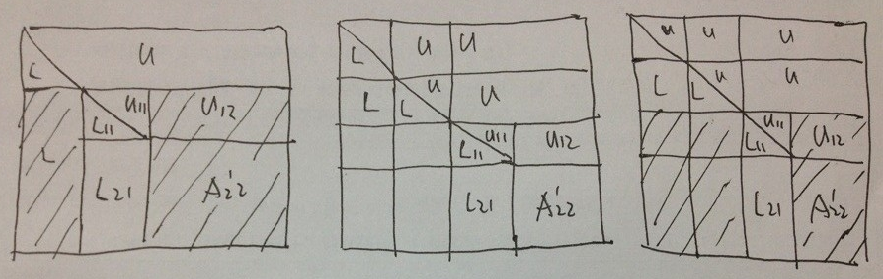
HPL优化思路
1.有关参数调优可以参考[https://www.jianshu.com/p/fc159fc46c55]
| 行号 | 参数说明 |
|---|---|
| 1~2 | 说明性文字,无需修改 |
| 3~4 | 用作保存测试结果的设置 |
| 5 | 选择测试矩阵的数量 |
| 6 | 矩阵的规模(阶数) |
| 7 | 矩阵分块的数量 |
| 8 | 矩阵分块的规模(阶数) |
| 9 | 处理器阵列按列排列或按行排列 |
| 10 | 二位处理器网格的数量 |
| 11~12 | 每个网格的行数和列数 |
| 13 | 测试的精度,无需修改 |
| 14~21 | LU分解的算法选择 |
| 22~23 | L的横向广播算法选择 |
| 24~25 | 横向通信的通信深度,一般为0、1、2 |
| 26~27 | U的列项广播算法选择 |
| 28~29 | L和U的数据存放格式,0为按列存放,1为按行存放 |
| 30 | 回代中使用,一般使用默认值 |
| 31 | 用于内存地址对齐,一般为8 |
| 2.HPL调用的BLAS(Basic Linear Algebra Subprograms)库,用来完成矩阵-向量运算,可以在网上找到别的库例如GOTO、OpenBLAS、Atlas、MKL、ACML等多个版本,需要用不同的库尝试是不是有更好的效果。 | |
| 3.HPL采用 MPI进行并行计算,其中计算的进程以二维网格方式分布,需要设定处理器阵列排列方式和网格尺寸,这同样需要小规模数据测定获得最佳方案。 |
如何再Intel平台上选择正确的Task数
为了获得最佳性能,您必须将资源规格与物理 NUMA 特性保持一致 - 请参阅有关 Slurm 资源分配的 ULHPC 技术文档
- 例如(IRIS):每个插槽 14 个核心,每个节点 2 个插槽(“物理”CPU)(28c/节点)
[-N <N>] --ntasks-per-node <2n> --ntasks-per-socket <n> -c <thread>- 全部的:
<N>× 2 ×2×<n>任务,每个任务都在<thread>线程上, 确保<n>××<thread>= 14(如果你的目标是全节点利用率) - 例如:(
-N 2 --ntasks-per-node 4 --ntasks-per-socket 2 -c 7总计:8 个任务)
- 全部的:
理清一些概念(非常重要!!!)
Slurm 节点 = 物理节点,指定为-N <#nodes>,计算集群中的一个实体节点。
Slurm Socket = 物理插槽/CPU/处理器,一个节点上可能插了多个处理器,这里的处理器指的是实体,平常买的那种一颗一颗的处理器,sockets可以通过lscpu查看。
Slurm CPU = 物理核心,非常绕的一点是,当我们真正在节点里编写SBATCH脚本时,cpu的概念是一颗cpu core,是一个核。